Note: This post was first a conference talk - check out the talk page for slides and recordings.
A little over a decade ago, I bought an electric kettle from Breville. The plug blew my mind.

I found myself asking, why don’t all plugs have a hole like this? (patents, probably.) It makes it very easy to unplug from a socket, rather than trying to wiggle it back and forth, maybe even lightly electrocuting yourself. And it is also very obvious to me how to use it. It allows for easy grabbing and pulling.
The simplicity and thoughtfulness of this design - this made me think, what else am I unknowingly struggle with?

This brought me to a book called The Design of Everyday Things, by Don Norman (which you might notice, is the inspiration to this article).
It’s got this nice coffee pot on the cover of the book - dubbed a “coffee pot for masochists”.
The premise of the book is about how design serves as the communication between object and user, and how to optimize that communication for a better experience.
Design is concerned with how things work, how they are controlled, and the nature of the interaction between people and technology.
– Don Norman, The Design of Everyday Things
The range of “things” is not limited to physical objects, like the Breville plug I’m in love with, or masochistic coffee pot on the book’s cover. It includes any artificial creation: software and digital interfaces, the layout of a conference room, a manual for an appliance, organizational structures, etc.
So, what makes design good?
Two of the most important characteristics of good design are discoverability and understanding.
– Don Norman, The Design of Everyday Things
Discoverability #
Breaking this down further, discoverability is described as: am I able to figure out what actions are possible and where and how to perform them?
Norman lays out 5 key elements to discoverability:
-
Affordances determine what actions are possible. It’s what a user can do with an object based on the user’s capabilities. Affordances aren’t a physical property; it’s the relation between the user and the object. A door affords opening if you can reach the handle. For a toddler, the door does not afford opening if they cannot reach the handle.
-
A signifier is some sort of perceivable cue about the affordance. Signifiers communicate where the action should take place. The term “signifier” exists in this context to make a clear distinction between the signal an affordance might provide to a person, which is entirely in the visible or perceptible part of an affordance, and the actual affordance itself. They are signals, labels, sounds, some sort of indicator. A flat panel on a door signifies the need to push it open.
-
Constraints are limitations or restrictions, and they give us clues that allow us to determine a course of action by limiting the possible actions available to us. There are a few types of constraints: they could be physical, like a mailbox slot that only allows letters to be dropped off and not packages. Or logical, where the last piece of the puzzle must go into only last space left. There’s also cultural and semantic constraints, where a red road sign typically means to stop.
-
A mapping is the relationship between a control and an action. When the mapping uses spatial correspondence between the layout of the controls and the devices being controlled, it is easy to determine how to use them. An example of a good mapping would be where you have two lights, and two light switches. The left light switch controls the left light, and vice versa.
-
Feedback should communicate clear, unambiguous information back the user in order to be effective. Immediate feedback is ideal. Delayed feedback can be disconcerting and lead to a feeling of user abandonment or failure. And then there is a delicate balance in the amount of feedback: too much feedback can be annoying and irritating to users; too little feedback can be as useless as no feedback at all. Feedback also needs to be prioritized (important messages/alerts vs. unimportant).
These 5 key elements of discoverability – affordances, signifiers, constraints, mappings, and feedback – they help to build up the second part of good design: understanding.
Understanding #
Understanding asks if its possible or easy for users to figure out how the product can be used. An understanding is developed by forming a conceptual or mental model of how something works. A conceptual model is just a collection of explanations, often very simplified.
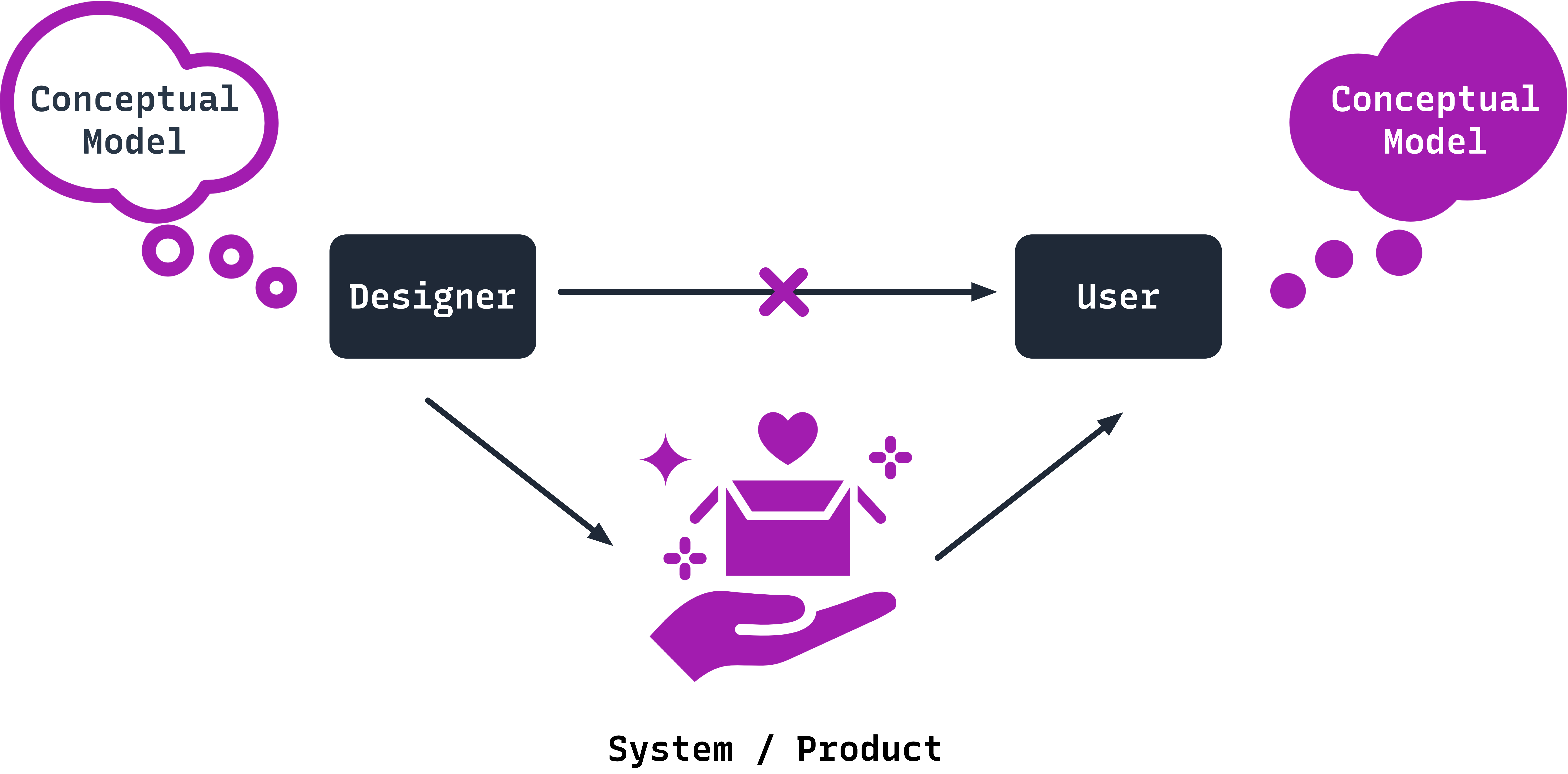
The user develops a conceptual model of their own on how a system or product works. A designer designs their system or product using their own conceptual model. Often, designers expect the user’s conceptual model to be identical to their own, but because they cannot communicate directly with the user, the burden of communication is with the system and its design.
Good conceptual models are the key to understandable, enjoyable products. And good communication is key to good conceptual models.
The communication comes from those key aspects of discovery - affordances, signifiers, constraints, mappings, and feedback.
Perhaps you’re starting to think about how these ideas - essentially “Human Centered Design” - can start to apply to software, to designing a library for others to use.

My first instinct when thinking about this is to think about libraries I’ve worked with, that maybe are not that fun to use. But then, I started to think: if I am an engineer who develops tools and infrastructure for other fellow engineers, how many masochistic coffee pots have I unknowingly shipped?
I am not at all an authority on API design. But for me, there’s a missing connection between the theory of good design and its actual implementation.
I condensed what I’ve learned this down to 3 tenets - 3 key principles - that make a delightful-to-work-with API.
Learn By Example: Pub/Sub Queue Service #
First, I want to set the stage. In a previous talk of mine, I went through building a chaos monkey-like system with a pub/sub queue. Let’s stick with that and let’s design a library to work with a pub/sub queue-like service. I’m just going to call it the Chaos Queue, because why not.
Client Library #
First, we have a class that defines the Message object, and all it does is contain data to be passed to and
from a chaos queue.
class Message:
def __init__(self, id: str, data: str, published_at: str) -> None:
self.id = id
self.data = data
self.published_at = published_at
We have a second class, a client that essentially publishes to and consumes messages from our chaos pub/sub queue.
class PubSubClient:
def __init__(self, topic: str, subscription: str) -> None: ...
def create_topic(self) -> None: ...
def create_subscription(self) -> None: ...
def add_message(self, msg: Message, timeout: int, retries: int) -> None: ...
def get_message(self, timeout: int, retries: int) -> Message | None: ...
def mark_message_done(self, msg_id: str, timeout: int, retries: int) -> None: ...
def clear_message_queue(self) -> None: ...
def close_client(self) -> None: ...
And this is our starting library! Perhaps you’re already thinking of some things that you want to change about this, which is good! But just hold tight.
User Code #
In order to develop a bit of empathy for my future users, I want to also write a bit of user code that interacts with my library.
So on the user-side, we create a chaos pub/sub queue client, and try to create a topic and subscription, catching if they already exists and continuing on.
import datetime
import uuid
import chaos_queue
TOPIC = ...
SUBSCRIPTION = ...
client = chaos_queue.PubSubClient(TOPIC, SUBSCRIPTION)
try:
client.create_topic()
except chaos_queue.TopicExists:
pass
try:
client.create_subscription()
except chaos_queue.SubscriptionExists:
pass
Then we start interacting with our instantiated client:
for i in range(5):
message = chaos_queue.Message(
id=str(uuid.uuid4()),
data=f"hello {i}",
published_at=datetime.datetime.now().isoformat()
)
try:
client.add_message(message, 1, 0)
except (chaos_queue.TimeoutError, queue.Full):
pass
while True:
message = client.get_message(2, 2)
if not message:
break
print(message)
# function defined elsewhere, use your imagination...
process_data(message.data)
client.mark_message_done(message, 0, 0)
client.close_client()
We first have a for-loop to publish 5 messages to our chaos pub/sub queue, and a while True loop to
consume those messages, we print the message (maybe that’s from some left-over debugging), and do some sort
of processing on the message data, then acknowledge the message from the queue when we’re done processing.
Finally, maybe the client has a couple of network connections that we need to clean up and close, maybe there are some buffers to flush.
Now, let’s improve this for the user, and start iterating on our library. We’ll start with the first of my 3 principles:
Intuitive #
An API should be intuitive.1 With an intuitive API, the user can be lazy. They won’t have to think too hard about how it works. They won’t have to remember complicated details because their intuition correctly explains them. They don’t have to spend a lot of time learning new parts of the API because it all works pretty similarly.
An intuitive API builds on a user’s pre-existing conceptual model, and tries not to do anything surprising; nothing that unnecessarily works against any logical or domain constraints.
With that, I have three changes I want to make to our chaos queue to improve the intuitiveness of the API.
Use Domain Nomenclature #
Let’s start with some low-hanging fruit, and name the methods in our client class using the domain’s nomenclature, like:
- publish a message to a queue;
- pull a message from the queue;
- acknowledging a message is complete;
- and drain a queue of messages.
In our PubSubClient, we’ve started with add_message, get_message, mark_message_done, and
clear_message_queue. Let’s rename to publish, pull, ack, and drain.
We’ll also drop the noun in the function name. I found it redundant because (at least in my mind),
the noun that we’re operating on is in the function signature: the msg.
class PubSubClient:
def __init__(self, topic: str, subscription: str) -> None: ...
def create_topic(self) -> None: ...
def create_subscription(self) -> None: ...
def publish(self, msg: Message, timeout: int, retries: int) -> None: ...
def pull(self, timeout: int, retries: int) -> Message | None: ...
def ack(self, msg_id: str, timeout: int, retries: int) -> None: ...
def drain(self) -> None: ...
def close_client(self) -> None: ...Naming Shouldn’t Be Hard #
The next suggested change steps back a tiny bit to think about appropriate abstraction levels. This idea might be a little controversial - but what I mean is if you find it difficult to name your classes or functions, or you find your object names to be a little awkward and clumsy, it’s an indication that you might have awkward abstractions.
In our PubSubClient, we have a few curious methods: create_topic, create_subscription, and
close_client. But this client seems to manage a lot in one object. From the user’s point of view,
what if we are just wanting to consume messages and not publish them, do I have to create a topic for some
reason? Will there be multiple connections managed by this client, maybe some unnecessary?
Let’s not add to any confusion for the user. So instead, let’s break up this client into two: one that just works with publishing, and one that works for subscribing. This also allows us to clean up the method names a little bit.
class PubClient:
def __init__(self, topic: str) -> None: ...
def create(self) -> None: ...
def publish(self, msg: Message, timeout: int, retries: int) -> None: ...
def close(self) -> None: ...
class SubClient:
def __init__(self, subscription: str) -> None: ...
def create(self) -> None: ...
def pull(self, timeout: int, retries: int) -> Message | None: ...
def ack(self, msg_id: str, timeout: int, retries: int) -> None: ...
def drain(self) -> None: ...
def close(self) -> None: ...This then creates natural constraints on what the user can do.
If the user must create a topic, they have to instantiate a PubClient, and are limited to only those
actions provided with the PubClient’s methods.
However, our clients also create some needless constraints on our users. Which brings me to my third change.
Provide Symmetry #
Let’s make sure our API has symmetry. We allow the user to create a topic, or create a subscription. But what does a user do if they want to change an existing topic or subscription? Or delete one?
Let’s not limit the user unnecessarily and provide symmetry with our methods:
class PubClient:
def __init__(self, topic: str) -> None: ...
def create(self) -> None: ...
def update(self, config: dict) -> None: ...
def delete(self) -> None: ...
def publish(self, msg: Message, timeout: int, retries: int) -> None: ...
def close(self) -> None: ...
class SubClient:
def __init__(self, subscription: str) -> None: ...
def create(self) -> None: ...
def update(self, config: dict) -> None: ...
def delete(self) -> None: ...
def pull(self, timeout: int, retries: int) -> Message | None: ...
def ack(self, msg_id: str, timeout: int, retries: int) -> None: ...
def drain(self) -> None: ...
def close(self) -> None: ...Just having the create method without its logical symmetric pair gives a misleading signifier to the user.
You can be certain that users have worked with other APIs that provide both a create and delete method,
a get and a set method, an upload and download method. It would be counterintuitive to either not
provide such functionality, or to provide that functionality but not follow convention in symmetrical naming.
Some of these changes may seem a bit contrived - it is hard to come up with a simple, succinct example that is also relatable. But hopefully the message comes through here.
Some changes that come later on could very well apply to this “intuitive” tenet, and I’m sure there are changes that I’m not even addressing that might apply here or in other circumstances, again I’m not the expert here.
But let’s move onto the next tenet!
Flexible #
An API should be flexible. Again, I mean flexible for the user (it’s a whole other post about writing flexible APIs for the maintainer / contributor).
Basically, a flexible API lets you do what you want.
In my point of view, a flexible API let’s users get started quickly with the more basic use cases, and then allows the user to adjust as they need to solve more complex problems.
Flexibility comes down to the question of, “How many problems can users solve once they learn the API?”
For this tenet, I have four changes I want to make to our chaos queue.
Provide Sane Defaults #
The first is providing sane defaults to the most common use cases.
Recall that we have some methods that work with publishing and consuming messages. The main resource these
methods are working with is the msg. The timeout and retry arguments are not required to the core
functionality of publishing, pulling, or acknowledging a message.
Also, I have often found myself, as a user, to not know what a good number of seconds a timeout should be, or how many retries I should be making.
class PubClient:
def __init__(self, topic: str) -> None: ...
def create(self) -> None: ...
def delete(self) -> None: ...
def update(self, config: dict) -> None: ...
def publish(self, msg: Message, timeout: int = 30, retries: int = 0) -> None: ...
def close(self) -> None: ...
class SubClient:
...As the API designer, I should make optional behavior as optional keyword arguments. Maybe 30 seconds is the most common timeout value; or maybe it comes from the default on the server side. And maybe it’s the default to have zero retries.
By moving a lot of optional settings into keyword arguments, it allows the user to focus on what is required of them.
This change also goes beyond the flexibility of an API. By forcing the use of keyword arguments and providing sane defaults, we limit the number and the order of positional arguments that the user has to remember.
For instance, both timeout and retries are integers. If they were positional arguments like before, the user could easily inverse them when calling the method. And this would safely pass type checkers.
Maybe we have many more optional keyword arguments for our methods, like a request ID, verbosity level, maybe a bunch more. If you have many many arguments (positional or keyword), you might want to step back because it might be another hint at some clumsy code. You could be unnecessarily exposing some complexity. With type hints and a lot of arguments, if folks can’t understand your type annotations, maybe you need to rethink and refactor.
Aside: Rethink Your Need to Use **kwargs
#
For libraries with automatic doc generation, instead of finding the list of arguments and their meaning in the documentation, users will see absolutely no information except the vague “it takes some keyword arguments”.
If the library has no documentation (which, shame on you), then the user can’t just simply look at the function signature - they must dive into the codebase to understand what these kwargs are and how they’re handled and passed around.
Note: I used kwargs in my slides for the sake of readability 🤓.
Aside/Post-Script: Rethink Repetitive Keyword Arguments #
As I was writing this post, I noticed the use of timeout: int = 30, retries: int = 0 in many of
the method signatures of these clients. This could be an opportunity to consider bringing these
keyword arguments up to the class as instance attributes that are set upon instantiation, e.g.:
class BasicClient:
def __init__(self, timeout: int = 30, retries: int = 0, ...) -> None:
self.timeout = timeout
self.retries = retries
...I would do this if it would make sense to have the same timeout and retries for all the methods,
and/or if they shouldn’t/wouldn’t change for every method call.
Minimize Repetition #
The second change I want to make to increase flexibility of our API is to minimize the user’s need to repeat
themselves. We did see a loop in the user’s code calling publish (née add_message) for each message:
# original user's code
for i in range(5):
message = chaos_queue.Message(...)
try:
client.add_message(message, 1, 0)
except (chaos_queue.TimeoutError, queue.Full):
pass
# user's code with changes made so far
for i in range(5):
message = chaos_queue.Message(...)
try:
client.publish(message)
except (chaos_queue.TimeoutError, queue.Full):
pass
In our PubClient, our publish method currently accepts one positional argument for msg.
To minimize forcing the user to repeatedly call publish for each message, we can accept multiple message
objects in the function signature by collecting them into *args and then do the repetitive work for them.
class PubClient:
def __init__(self, topic: str) -> None: ...
def create(self) -> None: ...
def delete(self) -> None: ...
def update(self, config: dict) -> None: ...
def publish(self, *msgs: Message, timeout: int = 30, retries: int = 0) -> None:
...
for message in msgs:
self._queue.put(message, timeout=timeout)
def close(self) -> None: ...The msgs argument will now be a tuple of Messages for us to iterate over instead of the user.
Be Predictable and Precise #
As I said earlier, the tenet of flexibility is meant for the user’s point of view. Providing flexibility to the user requires you to be predictable and precise in what you do for them.
If you recall, part of building that conceptual model – that understanding for the user – is providing constraints and feedback.
We provide flexibility in what we accept as input, but there needs to be a clear constraint with what we return. We shouldn’t make the user figure out what object type they got back from a method of ours.
Recall the pull method in our SubClient that returns a consumed Message, or returns None.
This doesn’t seem too precise or predictable.
The user has to check if they got a Message at all, or if they are dealing with None.
What’s the None use case here? It’s when there are no more messages in the queue to consume. If we look at
pre-existing APIs, like Python’s queue module, it raises an error when the queue is empty. That seems
pretty reasonable, so let’s update our function signature to only return a Message object, and then
raise if there are no messages in the subscription queue.
class SubClient:
def __init__(self, subscription: str) -> None: ...
def create(self) -> None: ...
def delete(self) -> None: ...
def update(self, config: dict) -> None: ...
def pull(self, timeout: int = 30, retries: int = 0) -> Message:
...
try:
return self._queue.get(timeout=timeout)
except queue.Empty:
raise ChaosEmptyError("Subscription queue is empty!")
def ack(self, msg_id: str, timeout: int = 30, retries: int = 0) -> None: ...
def drain(self) -> None: ...
def close(self) -> None: ...This reflects what Don Norman said: that feedback “should communicate clear, unambiguous information back the user in order to be effective.” We allow the user to be effective by being predictable and precise with what we return.
Let Users Be Lazy #
This last flexibility change I want to make again supports users being lazy. Basically, let’s not force users to provide data that you can generate yourself.
Recall the Message object, it has an id, some data, and a published_at timestamp of some sort.
Now when creating a Message, there’s no need for users to supply their own unique ID, or to timestamp it
with when it was published.
We can do that ourselves:
class Message:
def __init__(self, data: str, id: str | None = None, published_at: str | None = None):
self.data = data
self.id = id or str(uuid.uuid4())
self.published_at = published_at or datetime.datetime.now().isoformat()
def __repr__(self) -> str:
return f"Message(id={self.id}, published_at={self.published_at})"
publish method (particularly if the timestamp refers to the “published at” time).
But coming up with real-world examples is difficult, so just go along with me here.
Next, hopefully we have a bit of user understanding: often, the user may want to print or log a message for debugging purposes. For that, we should provide a __repr__ method to make it easy to just print out the instance. Now the user won’t need to worry about printing the necessary attributes on a message, but just the message itself.
So this is just one approach to re-defining our message object to help out the user.
We could also use data classes:
from dataclasses import dataclass, field
@dataclass
class Message:
data: str = field(repr=False)
id: str = field(default=None)
published_at: str = field(default=None)
def __post_init__(self):
self.id = self.id or str(uuid.uuid4())
self.published_at = self.published_at or datetime.datetime.now().isoformat()
This removes some boilerplate for us. It does get a little clumsy to set defaults in our case with using
__post_init__ - but it is still nice.
A third option would be to use the third-party package, attrs:
from attrs import define, field
@define
class Message:
data: str = field(repr=False)
id: str = field()
published_at: str = field()
@id.default
def set_id_default(self):
return str(uuid.uuid4())
@published_at.default
def set_published_at_default(self):
return datetime.datetime.now().isoformat()
If I needed, attrs would give me more to provide flexibility and constraints for my users, since not only
does it give me a clean way to set dynamic defaults, it also has validation, converters, even the ability
to abuse __init__ moreso if I needed. I’m not a paid shill for attrs - I’m just a happy user of it 🤩.
If your API is not flexible, you’ll find yourself saying, “I’m sorry, I know our API should be able to do that but for reasons that you don’t care about and are within our control, we can’t.”
If the API is not flexible, users eventually ditch the library and go to something else to solve their problems.
And now, for my last tenet.
Simple #
An API should be simple.
The complexity of an API can be measured by the cognitive load it requires to actually use it. Complexity hurts our understanding.
We’ve already made some changes to reduce the cognitive load of our API, like consistent and appropriate method naming, limiting the number of positional arguments in our function signatures, and minimizing the amount of repetition the user has to do. But we can make a few more changes to make our API more simple to use.
Provide Composable Functions #
The first change is to provide composable functions.
APIs that follow the mathematical closure property tend to be simple as well as flexible. Loosely, an API holds the closure property when every operation returns a data type that can be fed into other operations.
This means different operations in your API can be composed with each other. For example, in Python, we’re able to chain a bunch of string methods together since the output of many string methods is another string.
The closure property makes it easy to combine multiple operations to get the desired result. Maybe users don’t often do this, but following this where possible allows users to not have to remember differing function signatures operating on the same object.
Looking at our subscription client, we have two methods that operate on the Message object:
class SubClient:
def __init__(self, subscription: str) -> None: ...
def create(self) -> None: ...
def delete(self) -> None: ...
def update(self, config: dict) -> None: ...
def pull(self, timeout: int = 30, retries: int = 0) -> Message: ...
def ack(self, msg_id: str, timeout: int = 30, retries: int = 0) -> None: ...
def drain(self) -> None: ...
def close(self) -> None: ...It’s pretty reasonable to think that once you pull a message from the chaos queue, you’ll want to acknowledge it, otherwise it will get re-delivered after some time has passed, causing unnecessary duplicated work.
There’s no reason for us to be restrictive in our function signature for ack’ing and requiring a string. That adds to the cognitive load for the user - they have to remember that they must give the ID of the message they want to ack, and can’t just pass in the object they’ve been working with.
So let’s just change that to take in a message object. We can figure out how to get the ID of the message from there.
class SubClient:
def __init__(self, subscription: str) -> None: ...
def create(self) -> None: ...
def delete(self) -> None: ...
def update(self, config: dict) -> None: ...
def pull(self, timeout: int = 30, retries: int = 0) -> Message: ...
def ack(self, msg: Message, timeout: int = 30, retries: int = 0) -> None: ...
def drain(self) -> None: ...
def close(self) -> None: ...So now it’s simpler for a user to pull a message from subscription and then to ack it.
While we’re at it, let’s accept the ability for users to give us multiple messages if they wish to batch up their acknowledgements. It also adds to the symmetry of our method signatures and removes unnecessary loops in user code.
class SubClient:
def __init__(self, subscription: str) -> None: ...
def create(self) -> None: ...
def delete(self) -> None: ...
def update(self, config: dict) -> None: ...
def pull(self, timeout: int = 30, retries: int = 0) -> Message: ...
def ack(self, *msgs: Message, timeout: int = 30, retries: int = 0) -> None: ...
def drain(self) -> None: ...
def close(self) -> None: ...While we’re on the topic of loops, the next change I want to make aligns our API with some Python idioms, making it more Pythonic.
Leverage Language Idioms (Part I) #
Leveraging language idioms also leans into what a programming language affords. Different programming languages allow you – or afford you – different approaches to the kinds of problems we solve. For instance, supporting reflection and introspection; or supporting default values for function parameters; or how to define an iterator.
So, looking again at our subscription client, the user has to call pull to get a single message; and
as you might recall, that the user code as a while True loop:
# original user code
while True:
message = client.get_message(2, 2)
if not message:
break
print(message)
# function defined elsewhere, use your imagination...
process_data(message.data)
client.mark_message_done(message, 0, 0)
# user's code with changes made so far
while True:
try:
message = client.pull()
except ChaosEmptyError:
break
print(message)
# function defined elsewhere, use your imagination...
process_data(message.data)
client.ack(message)
Let’s make it easier for the user and provide an iter method that returns an Iterator:
class SubClient:
def __init__(self, subscription: str) -> None: ...
def create(self) -> None: ...
def delete(self) -> None: ...
def update(self, config: dict) -> None: ...
def pull(self, timeout: int = 30, retries: int = 0) -> Message: ...
def iter(self, timeout: int = 30, retries: int = 0) -> Iterator[Message]:
...
while not self._queue.empty():
message = self._queue.get(timeout=timeout)
yield message
def ack(self, *msgs: Message, **kwargs) -> None: ...
def drain(self) -> None: ...
def close(self) -> None: ...Providing an iterator is helpful for cases like this, where the user is consuming a stream of events or data. It’s also helpful when users might need to page through results, like a search query with hundreds or thousands of items.
This iter method also happens to simplify the user’s code even more - the iterable just stops when there are no more messages. The user is now able to remove a try/except for an empty queue around their consuming code.
# Updated user code
for message in sub_client.iter():
print(message)
process_data(message.data)
sub_client.ack(message)
Leverage Language Idioms (Part II) #
In continuing on leveraging the language’s idioms, you might remember both clients have a close
method, managing any connections and buffers underneath the hood. This forces the user to remember
to clean up after themselves, adding to the complexity and cognitive
load. (You might see where this is going.)
Let’s make use of context managers and implement __enter__ and __exit__:
class PubClient:
def __init__(self, topic: str) -> None: ...
def create(self) -> None: ...
def delete(self) -> None: ...
def update(self, config: dict) -> None: ...
def publish(self, *msgs: Message, timeout: int = 30, retries: int = 0) -> None: ...
def close(self) -> None: ...
def __enter__(self) -> Self:
return self
def __exit__(self, *args) -> None:
self.close()We’re providing an easy way for users to not have to worry about remembering any finalization or cleanup behavior.
Leverage Language Idioms (Part III) #
There’s even a third adjustment we can make to align with existing idioms and habits.
We have two create methods on our PubClient and SubClient that for the user, would raise if a
topic or subscription already exists.
Let’s follow convention of other APIs like os.make_dir and even SQL’s CREATE TABLE, and allow
the user not to care if something exists already, and just make sure it exists.
class PubClient:
def __init__(self, topic: str) -> None: ...
def create(self, exist_ok: bool = False) -> None: ...
def delete(self) -> None: ...
def update(self, config: dict) -> None: ...
def publish(self, *msgs: Message, timeout: int = 30, retries: int = 0) -> None: ...
def close(self) -> None: ...
def __enter__(self) -> Self:
return self
def __exit__(self, *args) -> None:
self.close()We’ve added an exist_ok keyword, and had it default to False, since it may not do what a user expects,
so we force them to opt-in.
Now onto the last change!
Provide Convenience #
We can also think of simplicity as “convenient to get started”: How much do I have to learn to start being able to use this library? What do I have to do right now to get it working?
If the API is not convenient, if it takes many steps to get started, or I have to page through the docs in order to get the very basic understanding, then the tool’s adoption will suffer.
So, provide your user with convenience. And you do this by treating your README like you would a
newspaper. Give them the most important details first – above the fold – and if users want to
learn more, then they can “turn the page” and read through the rest of the document.
When I am looking at a README, I want three things “above the fold”:
- How do I get your library? Do I need any system-level or non-Python dependencies?
- What are one or two examples can I copy-paste immediately to try this out? Side note: reconsider if your examples are using the REPL. It makes it annoying to copy & paste the examples into code. Or maybe that’s just a pet peeve of mine.
- Where do I go for more information?
# README.md
## Installation
```sh
$ pip install chaos-queue
```
## Get Started
```python
import chaos_queue
messages = [chaos_queue.Message(str(i)) for i in range(5)]
pub_client = chaos_queue.PubClient(TOPIC)
with pub_client.create():
pub_client.publish(*messages, timeout=1, retry=0)
```
## Learn more
Just go to [chaos-queue.readthedocs.io] for documentation and more examples!So give me those three things at the top, and I’m good to go to get started with your API.
Rewind #
We started here, with a very simple API that only contained two classes:
# before
class Message:
def __init__(self, id: str, data: str, published_at: str) -> None:
self.id = id
self.data = data
self.published_at = published_at
class PubSubClient:
def __init__(self, topic: str, subscription: str) -> None: ...
def create_topic(self) -> None: ...
def create_subscription(self) -> None: ...
def add_message(self, msg: Message, timeout: int, retries: int) -> None: ...
def get_message(self, timeout: int, retries: int) -> Message | None: ...
def mark_message_done(self, msg_id: str, timeout: int, retries: int) -> None: ...
def clear_message_queue(self) -> None: ...
def close_client(self) -> None: ...As we went on, we broke our code into three classes:
# after
@define
class Message:
data: str = field(repr=False)
id: str = field()
published_at: str = field()
@id.default
def set_id_default(self):
return str(uuid.uuid4())
@published_at.default
def set_published_at_default(self):
return datetime.datetime.now().isoformat()
class PubClient:
def __init__(self, topic: str) -> None: ...
def create(self, exist_ok: bool = False) -> None: ...
def delete(self) -> None: ...
def update(self, config: dict) -> None: ...
def publish(self, *msgs: Message, timeout: int = 30, retries: int = 0) -> None: ...
def close(self) -> None: ...
def __enter__(self) -> Self:
def __exit__(self, *args) -> None: ...
class SubClient:
def __init__(self, subscription: str) -> None: ...
def create(self, exist_ok: bool = False) -> None: ...
def delete(self) -> None: ...
def update(self, config: dict) -> None: ...
def pull(self, timeout: int = 30, retries: int = 0) -> Message: ...
def iter(self, timeout: int = 30, retries: int = 0) -> Iterable[Message]: ...
def ack(self, *msgs: Message, timeout: int = 30, retries: int = 0) -> None: ...
def drain(self) -> None: ...
def close(self) -> None: ...
def __enter__(self) -> Self: ...
def __exit__(self, *args) -> None: ...So we went from 14 lines of code to 32 (not including imports). And that’s okay, because we started with a lot of user code, 27 lines to be exact:
client = chaos_queue.PubSubClient(TOPIC, SUBSCRIPTION)
try:
client.create_topic()
except chaos_queue.TopicExists:
pass
try:
client.create_subscription()
except chaos_queue.SubscriptionExists:
pass
for i in range(5):
message = chaos_queue.Message(
id=str(uuid.uuid4()),
data=f"hello {i}",
published_at=datetime.datetime.now().isoformat()
)
try:
client.add_message(message, 1, False)
except (chaos_queue.TimeoutError, queue.Full):
pass
while True:
message = client.get_message(2, True)
if not message:
break
print(message)
process_data(message.data)
client.mark_message_done(message, None, False)
client.close_client()And got it down to just 13 lines:
messages = [chaos_queue.Message(data=f"hello {i}") for i in range(5)]
with chaos_queue.PubClient(TOPIC) as pub_client:
pub_client.create(exist_ok=True)
try:
pub_client.publish(messages, timeout=1)
except chaos_queue.TimeoutError:
pass
with chaos_queue.SubClient(SUBSCRIPTION) as sub_client:
sub_client.create(exist_ok=True)
for message in sub_client.iter():
print(message)
process_data(message.data)
sub_client.ack(message)This should be the goal - not necessarily the number of lines of code, but it’s about user empathy when designing a “delightful” API.
So, to recap:
- Is your API intuitive for the user?
- Is it flexible for their use cases?
- Is it simple enough to essentially learn once?
You have to keep in mind, your software will become a part of a larger system — your only choice is whether it will be a well-behaved part of that larger system.
– clig.dev
But the “how” can be a little elusive. So hopefully, this example progression in improving a dummy API is helpful.
But it’s a lot to remember, I know. So if you remember only one thing this post, then remember this:
If all else fails, standardize.
– Don Norman, The Design of Everyday Things
Don Norman leaves us with a good catch-all: When no other solution appears possible, then design everything the same way, so people only have to learn once.
References #
I used a lot of resources to help me pull this all together. Here’s everything I referred to, in no particular order:
- The Design of Everyday Things wiki, Amazon - Don Norman
- A Brief, Opinionated History of the API - talk by Joshua Bloch at QCon New York 2018
- How to Design a Good API and Why It Matters (video) (slides) (PDF) - talk for Google TechTalks by Joshua Bloch in 2006.
- Simple Made Easy - talk by Rich Hickey at Strange Loop 2011
- How to design APIs that other people like to use - Anna Tisch (Kiwi Pycon X, 2019)
- Łukasz Langa - Keynote from PyCon US 2022
- CLI Guidelines – An open-source guide to help write better command-line programs
- Patterns for Cleaner API Design – 2019 talk recording by Paul Ganssle (slides)
- Tell Dont Ask by Martin Fowler – Tell-Don’t-Ask is a principle that helps people remember that object-orientation is about bundling data with the functions that operate on that data
- What Does OO Afford? - Sandi Metz (author of ‘99 Bottles of OOP’)
- Affordances and Programming Languages - Randy Coulman
- Affordances from Interaction Design
- APIs as Ladders - Sebastian Bensusan (Stripe)
- Ruby vs Python comes down to the for loop - Doug Turnbull (Shopify)
-
Note that I mean intuitive for the user, not exactly for you, the implementer and maintainer. ↩︎